あなたはソーシャルメディアで流れるクリップを見たことがあるでしょう。まるで映画の予告編のような、映画的な10秒のショート動画です。クリアな映像、滑らかな動き、意図的に演出されたように見える照明。そして、あなたは思うのです。「自分もああいうものを作りたい」と。
そして、あなたは試してみます。
お気に入りのAI動画ツールに、「雨の中を歩く猫、映画的」といった文章を入力し、生成ボタンを押します。そして返ってくるものは…まあ、そこそこです。猫がいて、歩いていて、確かに雨は降っています。しかし、オンラインで見たあの衝撃的なクリップには到底及びません。
何が悪かったのでしょうか?
実は、ほとんどの人がAI動画ツールをその潜在能力のほんの一部しか活用できていません。それは技術に限界があるからではなく、誰も効果的にコミュニケーションを取る方法を教えてくれなかったからです。
AI動画のための良いプロンプトを書くことは、より創造的であることではありません。より正確であることなのです。その方法をご紹介します。
根本的な転換:脚本家ではなく、監督のように考える
最もよくある間違いはこれです。人々はAI動画のプロンプトを、友人に画像を説明するのと同じように書きます。一文だけ。漠然とした雰囲気。形容詞の羅列。
しかし、Seedance 2.0(PicMa Studioのテキスト読み上げ動画機能を支えています)のようなAI動画モデルは、画像生成機ではありません。時間ベースのモデルです。画面上に何が表示されるかだけでなく、いつ何が起こるかを理解する必要があります。
こう考えてみてください:あなたはキャプションではなく、ストーリーボードを書いているのです。
アマチュアとプロレベルのプロンプトの違いは、たった一つのことに集約されます:構造です。

具体的な比較を見てみましょう:
❌ アマチュアのアプローチ:夜の雨の街並みを歩く女性、ムーディーな雰囲気、ウォン・カーウァイ風。
✅ プロのアプローチ:
スタイル:ウォン・カーウァイ映画風、ネオンに照らされた濡れた路地、青緑と琥珀色のトーン
尺:12秒
ムード:雨の夜、メランコリック、静かな孤独感
[00:00-00:04] ミディアムショット:暗いコートを着た人物が左から入場、赤い傘をさし、雨の中をゆっくりと歩く、霧の中の街灯のハロー
[00:04-00:08] クローズアップ:傘の表面に当たる雨粒、カメラがゆっくりと押し寄せる、水たまりに映るネオンサイン
[00:08-00:12] オーバーショルダー:人物が霧の中に消えていく路地を見下ろす、フェードアウト
オーディオ:柔らかなジャズピアノ、遠くの雨のアンビエンス、濡れた石に響く足音
違いが分かりますか?2番目のバージョンは、AIに完全な設計図を与えています。各セグメントで何が起こるか、カメラがどのように動くか、感情的なトーンがどうあるべきかをモデルに伝えています。
プロレベルのプロンプトの5つの核となる原則
何百もの成功したプロンプトを分析した結果、アマチュアの結果とプロ品質の出力を分けるテクニックをご紹介します。
1. 動画を時間セグメントに分割する
これは、AI動画プロンプトにおいて最も重要なテクニックです。
動画全体を1つのブロックとして説明するのではなく、3~5秒のセグメントに分割します。[00:00-00:04]のようなタイムスタンプを使用して、各瞬間に何が起こるべきかをモデルに正確に伝えます。
なぜこれが効果的なのでしょうか?AI動画モデルは時間をシーケンスで処理します。各間隔で何が起こるかを指定することで、モデルにロードマップを与えることになります。最初の4秒はミディアムショット、次の4秒はクローズアップ、最後の4秒はオーバーショルダー視点に引くことをモデルは理解します。
このテクニックは、カメラ言語について考えることも強制します。[00:00-00:04] クローズアップと書くと、AIはこれが特定のタイプのフレーミングと被写界深度を意味することを理解します。モデルに組み込まれた映画文法の理解を活用しているのです。

2. すべての形容詞を具体的にする
「映画的」「美しい」「ムーディー」といった言葉は、AIプロンプトではほぼ役に立ちません。それらは主観的です。AIにはあなたの意図が全く分かりません。
代わりに、測定可能で説明的な言葉を使用しましょう:
| 以下の代わりに... | 次のように書く... |
|---|
| 「映画的な照明」 | 「暖かい金色のサイドライト、浅い被写界深度」 |
| 「かっこいい美学」 | 「青緑とマゼンタのカラーグレーディング、ネオンの反射」 |
| 「高品質」 | 「4K、フォトリアリスティック、35mmフィルムグレイン」 |
| 「劇的な雰囲気」 | 「ハイコントラスト、深い影、被写体へのリムライト」 |
具体的であればあるほど、出力はあなたのビジョンに近づきます。特定のビジュアルスタイルが欲しい場合は、そのスタイルを体現する監督の名前を挙げてください。「ウォン・カーウァイ風」は、ハンドヘルドカメラワーク、暖かい琥珀色の光、ネオントーンをもたらします。「ドゥニ・ヴィルヌーヴの撮影技法」は、冷たい構図、ネガティブスペース、ゆっくりとしたトラッキングショットをもたらします。
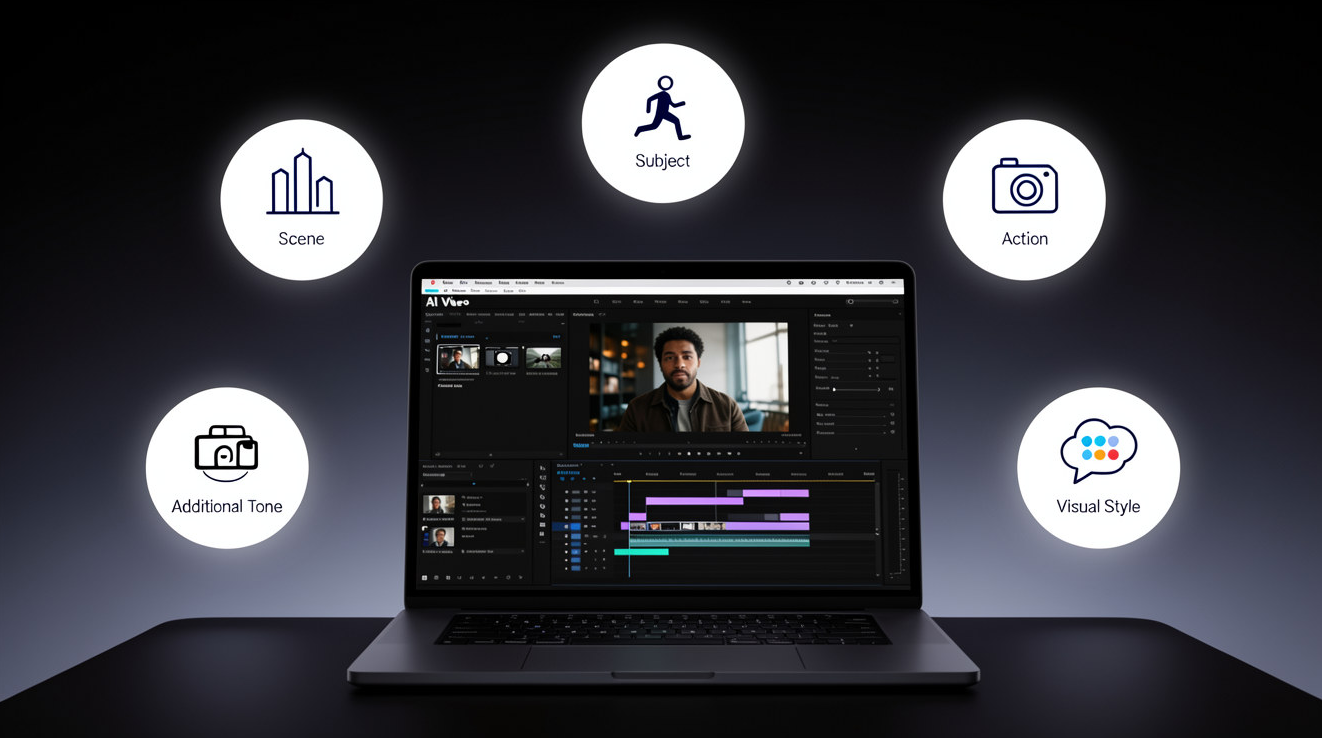
3. 6つの必須要素を定義する
効果的なプロンプトはすべて、6つの重要な要素をカバーする必要があります。これらのいずれかが欠けていると、AIに推測を任せることになり、大抵は間違った推測をされます。
- シーン — どこで行われているのか?
- 被写体 — 誰または何が焦点か?
- アクション — 何が起こるのか?何が動くのか?
- カメラの動き — カメラはどのように振る舞うか?
- 感情的なトーン — 視聴者はどのような感情を得るべきか?
- ビジュアルスタイル — どのように見えるか(色、照明、質感)?
生成ボタンを押す前の簡単なチェックリストが、がっかりする結果を防ぐことができます。
4. ネガティブプロンプトを忘れない
これは、AI動画プロンプトにおいて最も見落とされがちなテクニックの一つです。ネガティブプロンプトは、AIに表示したくないものを伝えます。
なぜこれが重要なのでしょうか?ネガティブな制約がないと、AIは余分なオブジェクト、歪んだ顔、不自然な動きなど、不要な要素を追加する可能性があります。商用アプリケーションでは、AI動画の失敗の80%以上が、モデルの能力ではなく、プロンプトの制約が不十分なことに起因しています。
良い汎用ネガティブプロンプトは次のようになります:
歪みなし、ちらつきなし、不自然な動きなし、余分なオブジェクトなし、ぼやけた解像度なし、透かしなし、テキストなし、カメラの揺れなし、不自然なカットなし
5. 参照入力を追加するタイミングを知る
ここに、PicMa Studioが純粋なテキストベースのツールに対して持つ独自の利点があります。PicMaの動画生成は複数の入力タイプをサポートしています。テキストだけに制限されるわけではありません。
- 画像参照:写真を動画の開始点としてアップロードします。AIはその画像の構図、色、被写体を生成アニメーションの基礎として使用します。これは、製品動画でブランドの一貫性を維持したり、既存のビジュアルのバリエーションを作成したりする場合に特に強力です。
- マルチモーダル入力:PicMaのSeedance 2.0統合により、テキスト、画像、さらには動画参照を1つのプロンプトで組み合わせることができます。これにより、前例のない制御が可能になります。ビジュアル参照には画像を、動作指示にはテキストを、そして雰囲気のガイダンスにはオーディオを使用します。

すぐに使えるプロンプトテンプレート
上記のすべての原則を組み込んだテンプレートをご紹介します。この構造は、PicMa StudioのSora2機能でのテキスト読み上げ動画生成に使用できます。
【スタイル】[監督/スタイル参照 + ビジュアルトーン + カラーパレット]
【尺】[合計秒数]
【ムード】[照明 + 天気 + 感情的なトーン]
[00:00-00:04] ショット1:[ショットタイプ + 被写体のアクション + 環境の詳細]
[00:04-00:08] ショット2:[ショットタイプ + 被写体のアクション + 環境の詳細]
[00:08-00:12] ショット3:[ショットタイプ + 被写体のアクション + 環境の詳細]
【オーディオ】(オプション) [背景音楽または音の説明]
【ネガティブ】(オプション) [避けるべき要素]
製品動画の実例(PicMaのワークフローを使用):
スタイル:クリーンなコマーシャルフォトグラフィー、柔らかい自然光、ミニマルな白い背景
尺:8秒
ムード:プロフェッショナル、高級感、魅力的
[00:00-00:04] ミディアムショット:木製テーブルの上の白い磁器マグカップ、穏やかなプッシュイン、柔らかな影、左からの自然光
[00:04-00:08] クローズアップ:マットな質感を明らかにするゆっくりとした回転、立ち上る湯気、暖かい琥珀色のトーン
ネガティブ:歪みなし、ちらつきなし、余分なオブジェクトなし、透かしなし、テキストなし、不安定な動きなし
PicMa Studioがこのワークフローをどのようにサポートするか
PicMa Studioは、単なるもう一つのAI動画ツールではありません。上記で説明した正確なプロンプトワークフローを、いくつかの重要な方法でサポートするように設計されています。
- Sora2テキスト読み上げ動画生成:PicMaは最近Sora2をリリースしました。これにより、テキストの説明から直接動画を生成できます。構造化されたプロンプトを入力し、向きと尺を選択すれば、AIが残りを処理します。
- 複数の生成モード:テキストから開始したり、画像から開始したり、または両方を組み合わせたりできます。製品写真をアップロードし、動きのテキスト指示を追加します。または、テキストから画像を生成し、その画像を動画に変換します。この「テキスト → 画像 → アニメーション」ワークフローは、非常に創造的な柔軟性をもたらします。
- 生成前の画像強化:動画に進む前に、PicMaの写真補正ツールがソース画像を改善できます。より良い入力 = より良い出力です。写真補正、背景削除、製品画像補正などのツールにより、開始時のビジュアルを可能な限り強力なものにします。
- すぐに使えるテンプレート:プロンプトをゼロから作成する準備ができていない場合、PicMaは画像と動画の両方に対する事前設計されたテンプレートのライブラリを提供します。スタイルを選択し、コンテンツをアップロードすれば、数秒で洗練された結果が得られます。
- 30秒の処理:ほとんどの動画は1分以内に生成され、無料ティアでも最大1080p、透かしなしの出力が得られます。
今日からこれを試し始めましょう
AI動画における「まあまあ」と「素晴らしい」の差は、モデルにどれだけ明確にあなたのビジョンを伝えられるかにかかっています。構造化され、正確なプロンプトは、常に曖昧で会話的なプロンプトよりも優れた結果を生み出します。AIがどれほど進歩していても同じです。
こちらがあなたのアクションプランです:
- 一文のプロンプトを書くのをやめましょう。時間セグメント化された構造に切り替えてください。
- 曖昧な形容詞を、具体的で測定可能な説明に置き換えてください。
- ネガティブプロンプトを使用して、望ましくない出力を制限してください。
- 画像参照の追加を検討してください。特に一貫性が重要な場合に有効です。
- PicMa StudioのSora2機能を使用して、構造化されたプロンプトを試し、結果を実際に確認してみてください。
ツールは日々良くなっています。平凡な結果と並外れた結果の違いは、モデルが実際に理解する言語を話すことを学ぶことにあります。
関連記事:
 20
20
 日本語
日本語